
Java实现Elasticsearch全量数据检索方案
应用场景分析
Elasticsearch在设计时为了优化查询性能,默认配置下对未指定分页参数的查询请求仅返回前10条记录。但在实际业务中,我们经常需要获取符合特定条件的完整数据集。虽然可以通过设置较大的size参数临时解决问题,但随着数据规模的增长,这种方案存在明显缺陷:一方面可能超出预设的size限制,另一方面大数据量查询会导致响应延迟甚至超时。本文将介绍一种基于滚动查询的高效解决方案。
常规查询机制
首先我们观察标准查询行为。执行基础查询指令时:
GET crm_meiqia_conversation/_search
系统返回结果如图所示,确实仅显示10条记录

如需获取更多记录,可通过size参数调整返回数量,例如:
GET crm_meiqia_conversation/_search
{
"size":20
}
执行效果如图所示,此时返回指定数量的文档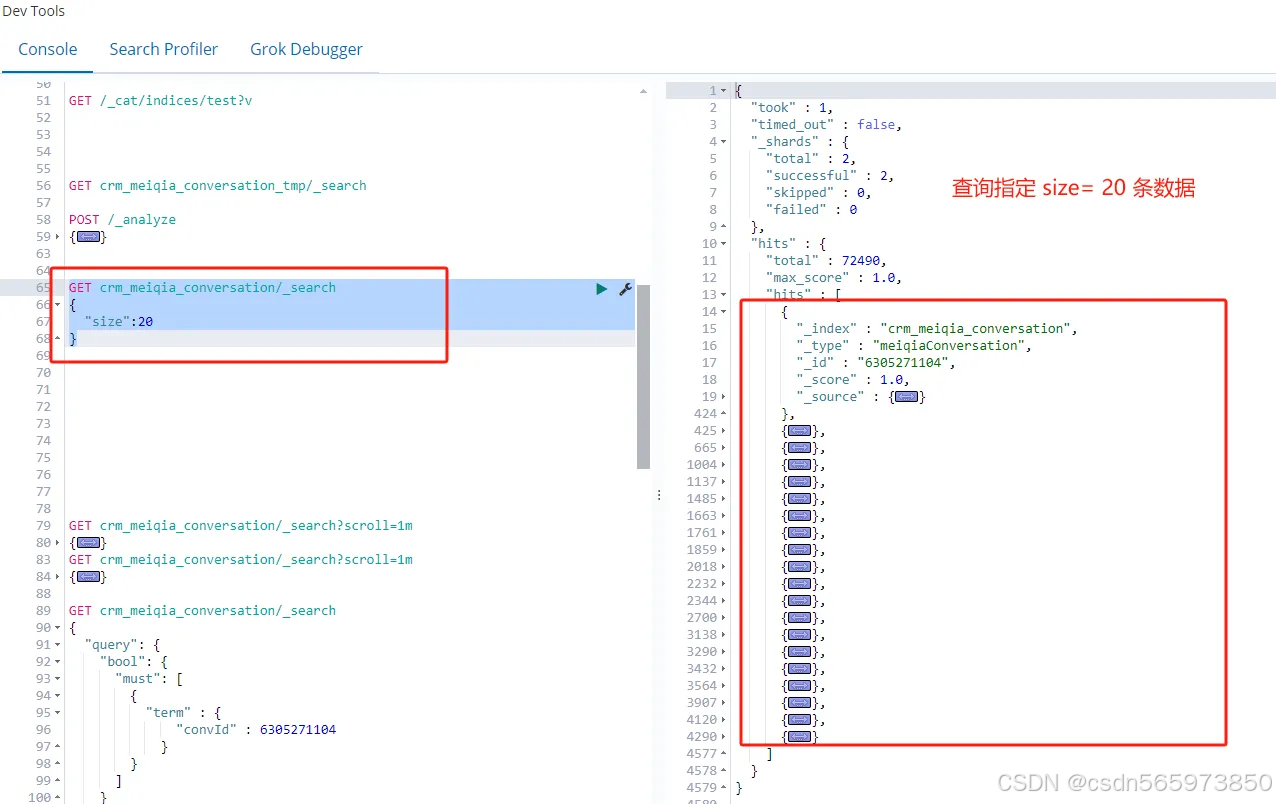
Java实现全量数据获取
通过Java API实现全量数据查询前,先观察最终实现效果。如图所示,结果集完整展示了符合条件的所有文档
未优化前的查询仅返回有限结果,如图所示
核心实现分为三个步骤:
1. 初始化滚动查询配置:
SearchRequestBuilder searchRequest = client.prepareSearch(index)
.setTypes(type)
.setQuery(query)
.setSize(100)
.setScroll(TimeValue.timeValueMinutes(1));
- 循环获取批次数据:
do {
searchResponse = client.prepareSearchScroll(scrollId)
.setScroll(TimeValue.timeValueMinutes(1))
.execute().actionGet();
// 处理批次数据
} while (hasMoreHits(searchResponse));
- 清理滚动会话:
ClearScrollRequest request = new ClearScrollRequest();
request.addScrollId(scrollId);
client.clearScroll(request).actionGet();
关键代码段如图所示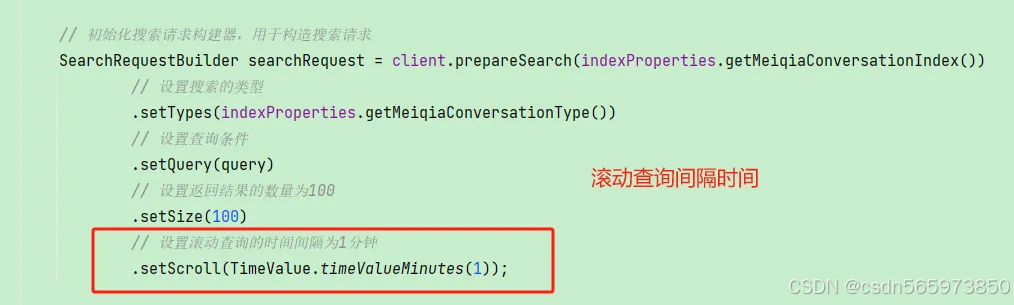
数据聚合过程如图所示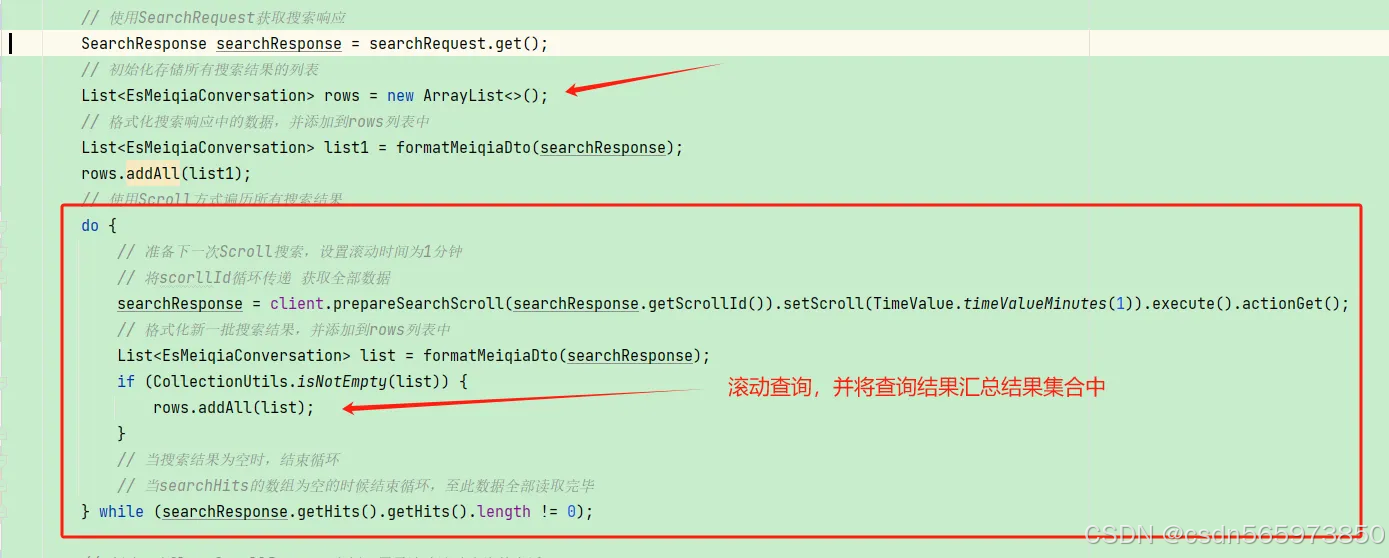
会话清理操作如图所示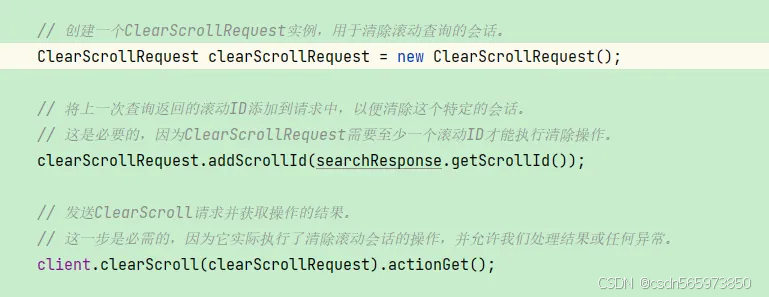
技术总结
虽然Elasticsearch常规查询已能满足多数场景需求,但在需要完整数据集的特殊情况下,滚动查询机制提供了可靠解决方案。该方案通过分批获取和内存会话管理,既保证了查询效率,又避免了大数据量带来的性能问题。建议开发者根据实际业务需求选择合适的数据获取策略。
文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/9268.html