
01基础库
1-1安装
依赖库:sqlalchemy
```python
pip install sqlalchemy
#直接安装即可
```
1-2导入使用
这里讲解思路【个人的理解】,具体写其实就是这个框架:
-
导入必要的接口【有创建
engine以及declarative_base】- 通过
create_engine接口创建engine,根据翻译可以翻译成引擎,和发动机一样,有了这个才能驱动数据库启动,但创建engine的接口接受的是一个针对 PostgreSQL的对象,对象的示例如:postgresql+psycopg2://scott:tiger@localhost:5432/mydatabase - 以下是官方对于这个
engine的解释:
- 通过
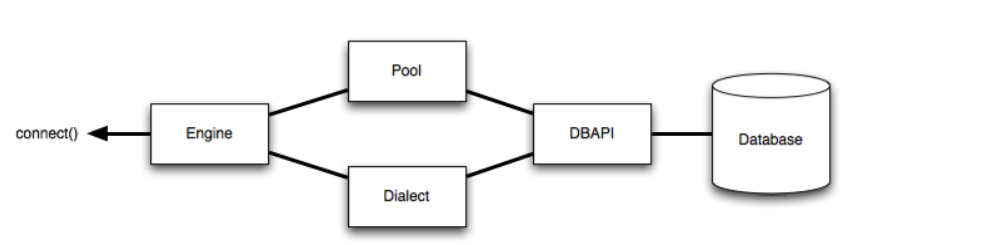

- 创建引擎
```pythondb_url = "sqlite:///database.db" #本地的sqlite数据库的地址,没有则自动创建
engine = create_engine(db_url) #调用数据库的url地址创建引擎
```
其中主要根据 sqlalchemy中的create_engine接口进行引擎的创建
create_engine(url: str | URL) -> Engine
其中URL就是上文提到的PostgreSQL的对象。这里是用sqlite,其他兼容数据库也可以使用,参照下图:
- 定义一个
sqlalchemyORM接口的基类,用于后续创建自定义的表、以及增删查改```pythonBase = declarative_base()
```
1-3 创建自己的表
-
前面的逻辑和导入使用是重合的,主要就是创建一个自己自定义的数据库表类 ->继承于上文提到的接口基类,进行表的创建
-
其中,使用
Column接口来创建表的列,这个接口接受主要两个变量:第一个是类型【Column, Integer, String, Float】。第二个使用到的是primary_key,即数据库的主键(数据库中数值唯一的一种属性,一般是数据库自动添加的,例如作为整形id,如果主键为TURE,则id这个属性的数值不会重复) -
Column(type_, *args, **kwargs)type_(必填):指定列的数据类型,例如Integer、String、DateTime等。-
primary_key(可选):是否为主键,默认为False。```python
from sqlalchemy import create_engine, Column, Integer, String, Float
from sqlalchemy.orm import declarative_base
db_url = "sqlite:///database.db"
engine = create_engine(db_url)
Base = declarative_base()
class User(Base):
tablename = "user"
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)Base.metadata.create_all(engine)
``` -
最后使用
Base.metadata.create_all(engine)接口创建这个数据库的所有表- 功能:
自动创建表 :create_all() 会基于模型中定义的表结构自动创建数据库表。如果表已经存在,则不会重新创建。
数据库初始化 :通常在应用程序第一次启动时,调用 create_all() 来创建数据库结构。
支持多个表 :create_all() 会创建所有在 Base 中定义的模型所对应的表。
1-4 all code
```python
from sqlalchemy import create_engine, Column, Integer, String, Float
from sqlalchemy.orm import declarative_base
db_url = "sqlite:///database.db"
engine = create_engine(db_url)
Base = declarative_base()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
def __repr__(self):#这个函数可以不用,不影响,为了能直接print这个类对象
return f"id:{self.id}, name:{self.name}, age:{self.age}"
Base.metadata.create_all(engine)
```
鸣谢以及参考:
文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/6199.html