
本文介绍基于Python 语言,针对一个文件夹 下大量的Excel 表格文件,基于其中每一个文件 内、某一列数据 的特征,对其加以筛选,并将符合要求 与不符合要求 的文件分别复制到另外两个新的文件夹 中的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中有大量的Excel 表格文件(在本文中我们就以csv格式的文件为例);如下图所示。

其中,每一个Excel 表格文件都有着如下图所示的数据格式。
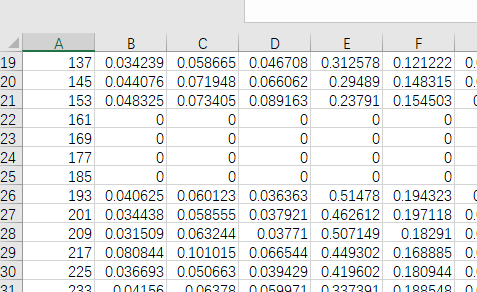
如上图所示,各个文件都有着这样的问题——有些行的数据是无误的,而有些行,除了第一列,其他列都是0值。因此,我们希望就以第2列为标准,找出含有0值数量低于或高于某一阈值 的表格文件——其中,0值数量多,肯定不利于我们的分析,我们将其放入一个新的文件夹;而0值数量少的,我们才可以对这一表格文件加以后续的分析,我们就将其放入另一个新的文件夹中。因此,计算出每一个表格文件对应的的0值数量百分比后,我们就进一步将这一Excel 表格文件复制到对应的文件夹内。
知道了需求,我们就可以开始代码的撰写。其中,本文用到的代码如下所示。
```python
# -*- coding: utf-8 -*-
"""
Created on Tue May 16 20:19:50 2023
@author: fkxxgis
"""
import os
import shutil
import pandas as pd
def filter_copy_files(original_path, useful_path, useless_path, threshold):
original_all_file = os.listdir(original_path)
for file in original_all_file:
path = os.path.join(original_path, file)
if file.endswith(".csv") and os.path.isfile(path):
df = pd.read_csv(path)
column_value = df.iloc[:, 1]
zero_count = (column_value == 0).sum()
zero_ratio = zero_count / len(column_value)
if zero_ratio < threshold:
new_path = os.path.join(useful_path, file)
shutil.copy(path, new_path)
else:
new_path = os.path.join(useless_path, file)
shutil.copy(path, new_path)
filter_copy_files("E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/13_AllYearAverage",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/LowMissingRate",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/HighMissingRate",
0.30)
```
其中,上述代码是一个筛选并复制文件的函数。该函数的目的是根据给定的阈值将具有不同缺失率的文件从一个文件夹复制到另外两个文件夹。
在代码中,filter_copy_files函数接受四个参数:
original_path:原始文件夹的路径,其中包含要筛选的.csv文件。useful_path:有用文件的目标文件夹路径,将满足阈值要求(也就是0值数量低于阈值)的文件复制到此处。useless_path:无用文件的目标文件夹路径,将不满足阈值要求(也就是0值数量高于阈值)的文件复制到此处。threshold:阈值,用于确定文件的缺失率是否满足要求。
函数首先使用os.listdir获取原始文件夹中的所有文件名,然后遍历每个文件名。对于以.csv结尾且为文件的文件,函数使用pd.read_csv读取.csv文件,并通过df.iloc[:, 1]获取第2列的值。
接下来,函数计算第2列中为零的元素数量,并通过将其除以列的总长度来计算缺失率。根据阈值判断缺失率是否满足要求。
如果缺失率小于阈值,函数将文件复制到useful_path目标文件夹中,使用shutil.copy函数实现复制操作。否则,函数将文件复制到useless_path文件夹中。
最后,我们调用了filter_copy_files函数,并传递了相应的参数来执行文件筛选和复制操作。
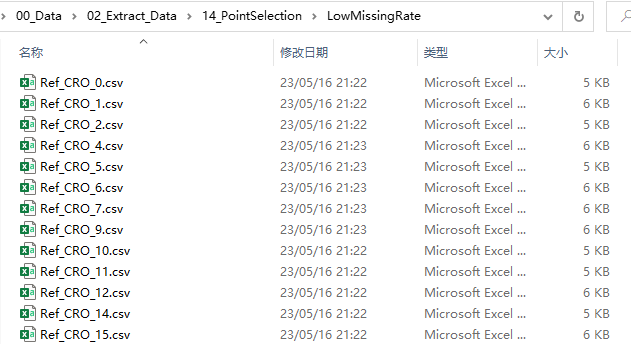
运行上述代码,我们即可在对应的文件夹中看到文件。如下图所示,0值数量低于阈值的表格文件都复制到了这个LowMissingRate文件夹中,我们即可对其加以后续处理;而那些0值数量高于阈值的表格文件,就放到另一个HighMissingRate文件夹中了。
至此,大功告成。
文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/6195.html